Everything You Need to Manage Incidents End-to-End
From the first alert to the final postmortem — detect, triage, respond, and resolve in one platform.
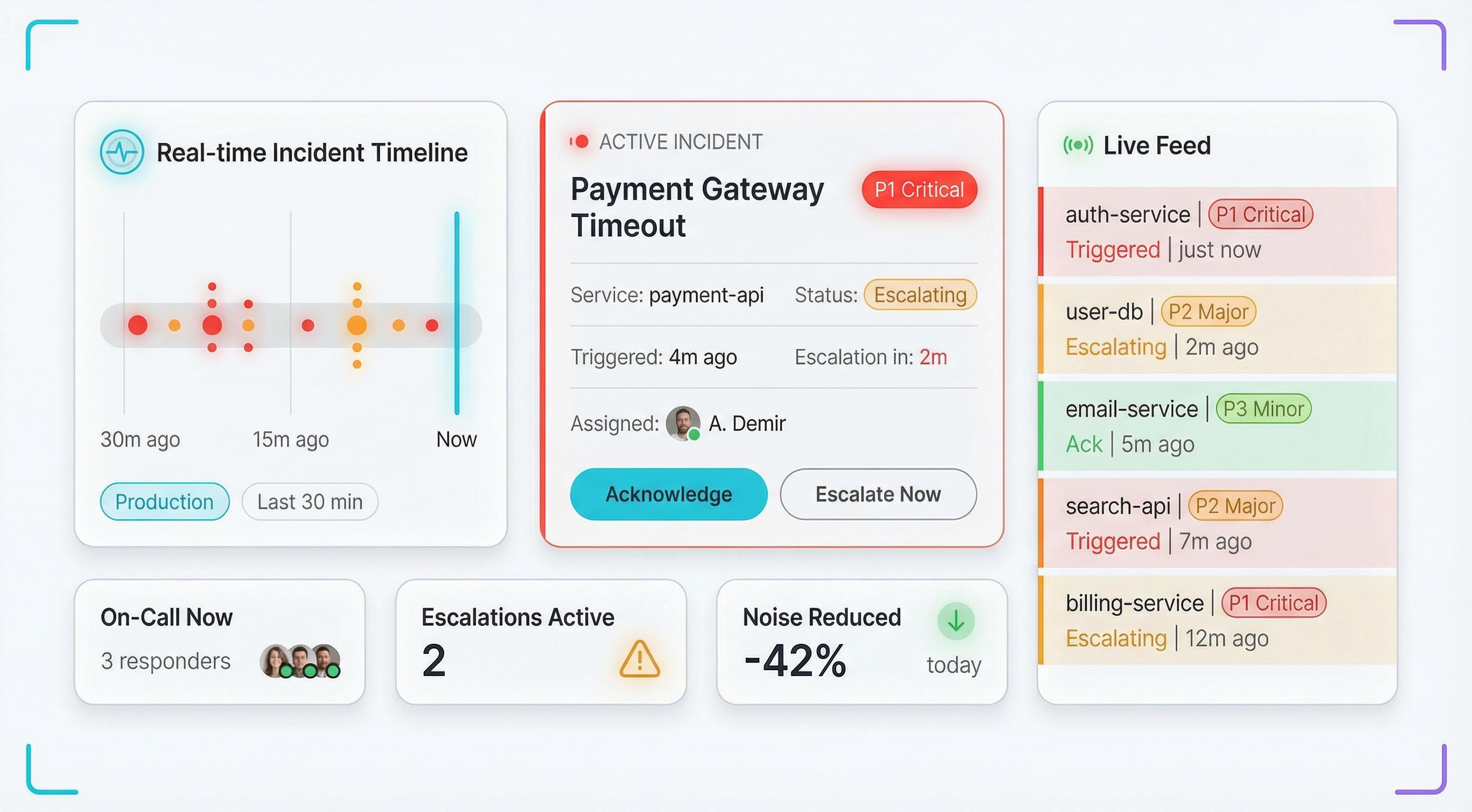
Real-time Alert Dashboard
See all active incidents, who's on-call, and current response status at a glance. Filter by severity, service, or team. Track MTTA and MTTR in real time — so you always know where things stand.
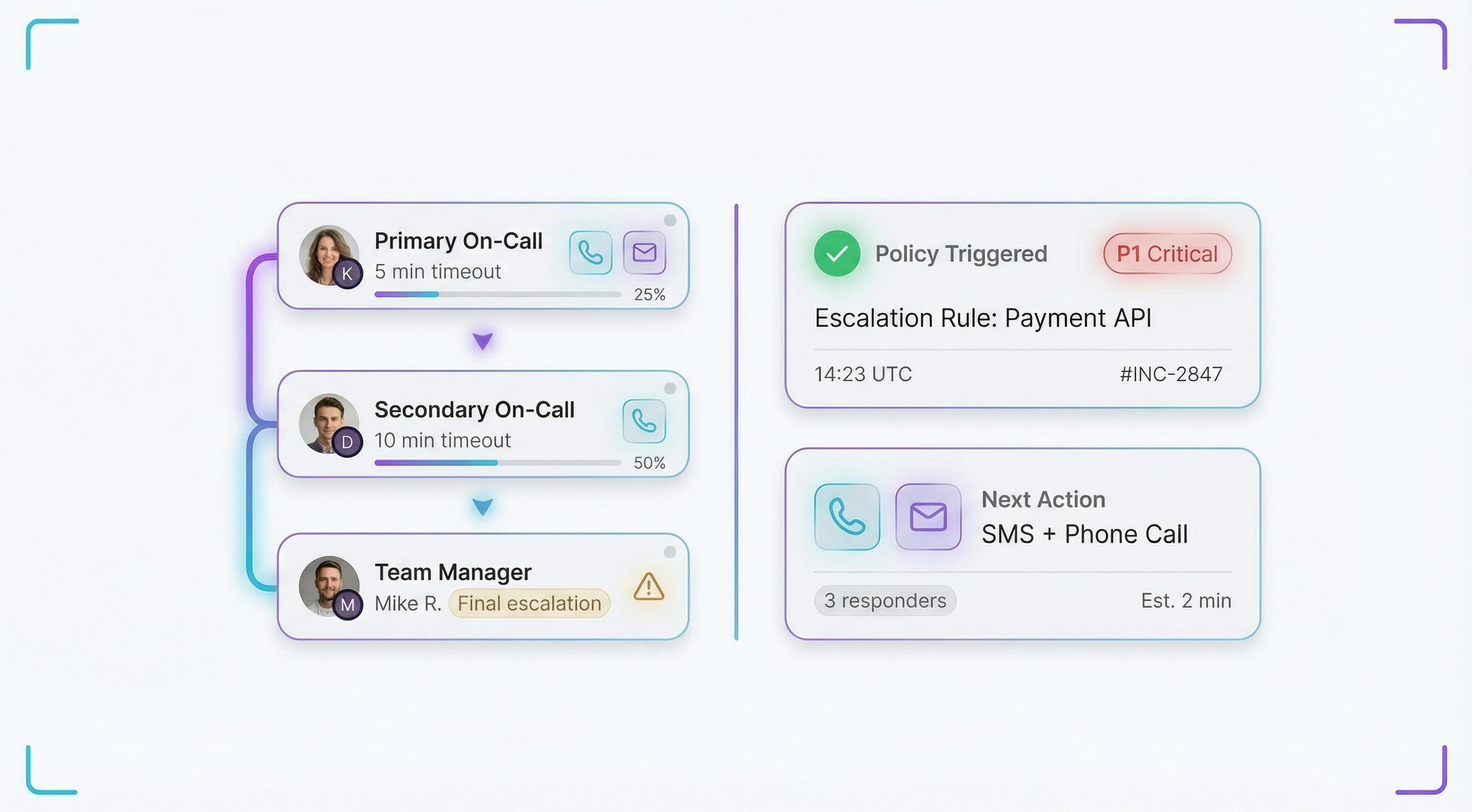
Smart Escalation Policies
Define multi-level escalation rules per team and severity. If an alert isn't acknowledged within your time window, it automatically escalates — via Slack, SMS, or phone call — until someone responds. No alert falls through the cracks.
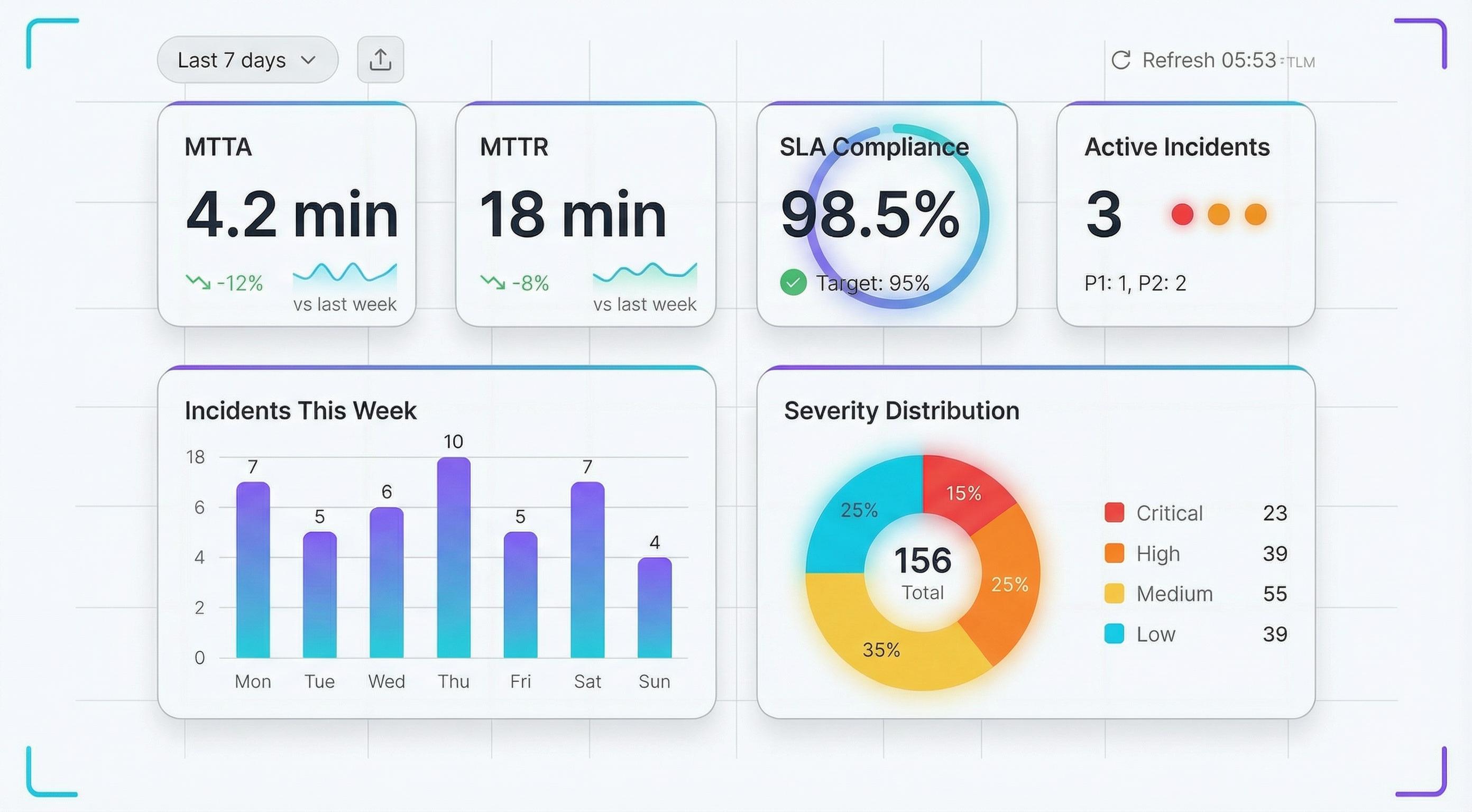
Incident Analytics
Track MTTA, MTTR, alert volume trends, and team workload distribution. Identify noisy services, spot recurring incidents, and measure improvement over time. Export reports for stakeholder reviews.
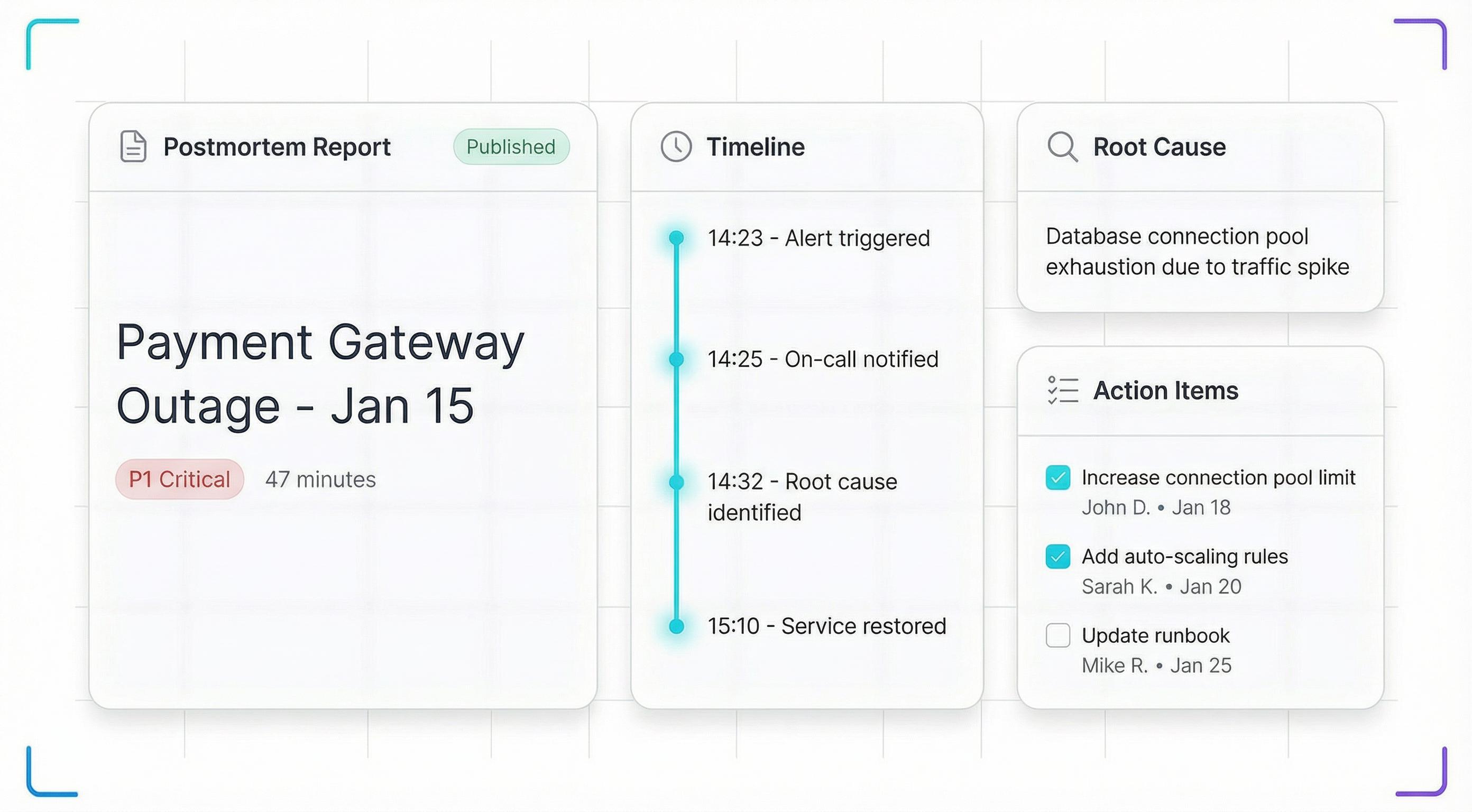
Postmortem & Incident Reviews
Auto-generated incident timelines with structured templates for root cause analysis. Assign action items, track follow-ups, and share postmortems with your team. Turn every incident into a learning opportunity — without spending hours writing documentation.
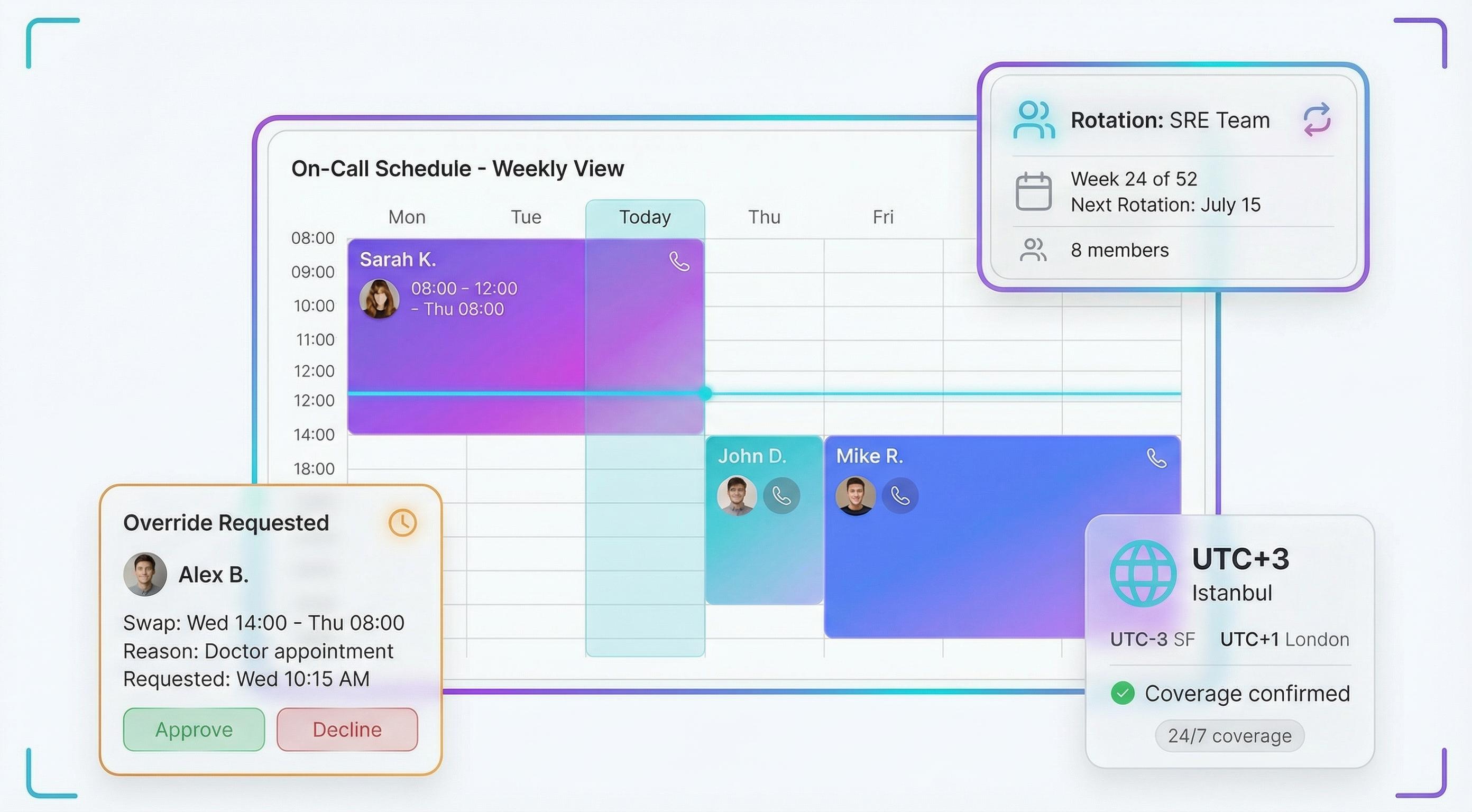
On-Call Scheduling
Create rotation schedules with drag-and-drop. Support for daily, weekly, and custom rotations with timezone awareness. One-click overrides and shift swaps — your team can manage their own schedule directly from Slack. Workload analytics help you distribute on-call fairly.
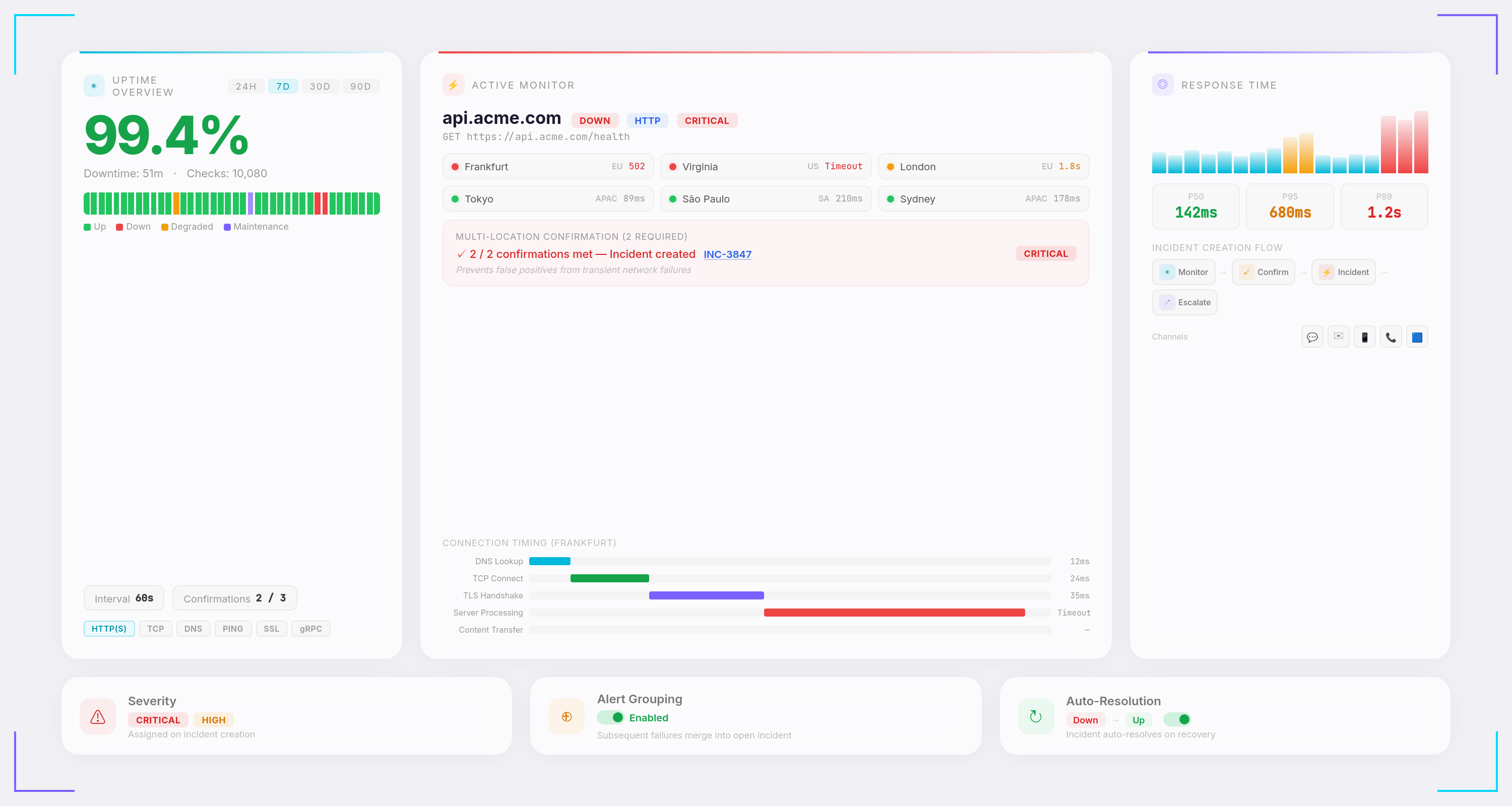
Synthetics Monitor
Proactively monitor your APIs, endpoints, and user flows from multiple locations worldwide. Run checks from Frankfurt, Virginia, Tokyo, São Paulo, London, and Sydney simultaneously. Get instant alerts the moment a check fails — before your users are impacted.
Connect Your Entire Monitoring Stack
Pre-built integrations with the tools your team already uses. Connect in minutes — no code, no agents, no complex setup.